1. 什么是数值字面量#
数值字面量(Numeric Literals)在编程中是表示特定数值的一个符号或一组符号。这些字面量用于直接在源代码中表示一个数值,无需进行任何计算。例如 123、3.14、0xFF、1.23e-4 都可以被视为数值字面量。
字面量的类型通常根据其格式和位置决定。例如在大多数编程语言[1][2][3]中,带有小数点的数字将被视为浮点数(如 3.14 ),而没有小数点的数字将被视为整数(如 123 )。
更复杂的编程语言可能支持其他类型的数值字面量,例如复数、大整数、无穷大、NaN(不是一个数字)等。
本章将从数值字面量的解析入手,开始进入编译器构造的世界。
Carbon数值类型介绍#
Carbon中数值类型[4][5]有如下几种:
整数类型
整数根据进制分为如下类型:十进制(例如 12345 )、十六进制(例如 0x1FE )、二进制(例如 0b1010 )等
实数类型
实数类型总是包含 . 符号,实数类型例如基础类型 123.456 以及科学技术法表示 123.456e789、0x1.2p123 等,其中科学技术法表示中的字符 e 及 p 在Carbon中称为指数(对应代码中exponent 字符,实际在幂运算中应为底数),对于一个十进制值 N 来说,e 相当于10±N,而 p 相当于2±N。
且实数类型字面量 exponent 字符后可跟随 + 或 - 字符,例如 12.34e+56 或 56.34e-12。
数字分隔符[6]
数字分隔符由下划线 _ 表示,例如十进制数: 1_23_456_7890、十六进制数: 0x7_F_FF_FFFF、实数: 2_147.48_3648e12_345 或 0x1_00CA.FE_F00Dp+2_4、二进制数: 0b1_000_101_11 等。
数值字面量词法解析:#
首先需要在字符串层面对数值字面量进行字符串切分,由于字符中数字分隔符即 _ 下划线只用于提升长数值的阅读性,对其不做处理,而其他字符如小数点及 exponent 字符需要获取其在字符串中所在位置,便于下一步的处理。于是在词法层面提供NumericLiteralToken类的抽象,需要存储的数据有:字符数据(text)、小数点字符位置(radix_point)、指数幂字符位置(exponent)。
以下代码参考numeric_literal section1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| class NumericLiteralToken {
public:
auto Text() const -> llvm::StringRef { return text; }
static auto Lex(llvm::StringRef source_text)
-> llvm::Optional<NumericLiteralToken>;
auto GetRadixPoint() -> int { return radix_point; }
auto GetExponent() -> int { return exponent; }
private:
NumericLiteralToken() {}
llvm::StringRef text;
// '.'字符的偏移量
int radix_point;
// 'e'或'p'字符的偏移量
int exponent;
};
|
其中我们重点关注Lex接口的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| auto NumericLiteralToken::Lex(llvm::StringRef source_text)
-> llvm::Optional<NumericLiteralToken> {
NumericLiteralToken result;
// 判断source_text是否为空以及第一个字符是否为数字
if (source_text.empty() || !IsDecimalDigit(source_text.front())) {
return llvm::None;
}
bool seen_plus_minus = false;
bool seen_radix_point = false;
bool seen_potential_exponent = false;
// 由于之前已经确认过首字符,这里索引从1开始
int i = 1;
for (int n = source_text.size(); i != n; ++i) {
char c = source_text[i];
if (IsAlnum(c) || c == '_') {
// 只支持小写的 'e',如果存在该字符且发现点号以及未探索
// 到加减号则记录exponent索引位置,否则继续下一轮循环
if (IsLower(c) && seen_radix_point && !seen_plus_minus) {
result.exponent = i;
seen_potential_exponent = true;
}
continue;
}
// 当前字符为 '.' 时,记录radix_point
if (c == '.' && i + 1 != n && IsAlnum(source_text[i + 1]) &&
!seen_radix_point) {
result.radix_point = i;
seen_radix_point = true;
continue;
}
// 当前字符为 '+' 或 '-' 时,记录seen_plus_minus
if ((c == '+' || c == '-') && seen_potential_exponent &&
result.exponent == i - 1 && i + 1 != n &&
IsAlnum(source_text[i + 1])) {
assert(!seen_plus_minus && "should only consume one + or -");
seen_plus_minus = true;
continue;
}
break;
}
// 返回探索到的字符串,以当前i的值为索引切分子串
result.text = source_text.substr(0, i);
// 记录 '.' 偏移
if (!seen_radix_point) {
result.radix_point = i;
}
// 记录 'e' 或 'p' 偏移
if (!seen_potential_exponent) {
result.exponent = i;
}
return result;
}
|
以上代码中,source_text用于接受外部传入的数值字符串,该类型为llvm::StringRef类型(StringRef类型分析可参考chapter12_s1.2: LLVM ADT StringRef介绍及使用),首先判断source_text是否为空以及第一个字符是否为数字,如果不满足条件则返回llvm::None,llvm::None实际为一个枚举数值类型,返回值为llvm::Optional(Optional类型分析可参考chapter12_s1.3: LLVM ADT Optional介绍及使用)。
接下来使用三个变量seen_plus_minus(是否探索到 + 或 - )、seen_radix_point(是否探索到 . )、seen_potential_exponent(是否探索到 e 或者 p )用于后续词法解析的条件判断。
在下一步字符串循环中,不断去除当前字符并做判断,直到不满足所以条件判断要求跳出循环。
跳出循环后记录对应数据存入返回值NumericLiteralToken对象的变量中。
数值字面量语法解析#
在词法层面我们切分并完成了NumericLiteralToken对象的解析,接下来需要实现数值字面量的解析,实现这一步的目标是在语义上能对不同数值字面量提取更多的信息,其中包括数值字面量的合规性检查、提取数据等,将数值字面量解析拆分为了Tokenizer和Parser两部分,使得每部分过程更为明确和便于后期扩展。
我们关注numeric_literal代码section2中的友元类Parser实现,将section1中NumericLiteralToken里两个函数GetRadixPoint和GetExponent的能力删除,将提取对应数据的能力移交至Parser,函数返回值改为llvm::APInt(参考阅读什么是APInt链接)。
以下代码参考numeric_literal section2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| class NumericLiteralToken::Parser {
public:
Parser(NumericLiteralToken literal);
auto IsInteger() -> bool {
return literal.radix_point == static_cast<int>(literal.Text().size());
}
auto GetRadix() const -> int { return radix; }
auto GetMantissa() -> llvm::APInt;
auto GetExponent() -> llvm::APInt;
private:
NumericLiteralToken literal; // 存储对应字面量
// 基数默认为10,可以为 2 或 10 或 16
int radix = 10;
// 词法结构:[radix] int_part [. fract_part [[ep] [+-] exponent_part]]
llvm::StringRef int_part; // 整数部分
llvm::StringRef fract_part; // 小数部分
llvm::StringRef exponent_part; // 指数部分
// 对应数据是否需要清除`_`或`.`符号,默认为false
bool mantissa_needs_cleaning = false;
bool exponent_needs_cleaning = false;
// 在`exponent`部分后面发现了`-`符号
bool exponent_is_negative = false;
};
|
具体看一下Parser的构造函数,构造时传入NumericLiteralToken对象,根据该对象里的radix_point数据进行int_part数据的切分,并对切分结果前两个字符做检查,根据0x或0b首字符判断进制,随即切分fract_part数据以及exponent_part数据,并判断是否在exponent部分后面发现了-符号。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| NumericLiteralToken::Parser::Parser(NumericLiteralToken literal)
: literal(literal) {
int_part = literal.text.substr(0, literal.radix_point);
if (int_part.consume_front("0x")) {
radix = 16;
} else if (int_part.consume_front("0b")) {
radix = 2;
}
fract_part = literal.text.substr(literal.radix_point + 1,
literal.exponent - literal.radix_point - 1);
exponent_part = literal.text.substr(literal.exponent + 1);
if (!exponent_part.consume_front("+")) {
exponent_is_negative = exponent_part.consume_front("-");
}
}
|
Parser构造函数中构建好数据后,需要提供接口获取对应数据。
其中包括四个函数接口:
1
2
3
4
| auto IsInteger() -> bool;
auto GetRadix() const -> int;
auto GetMantissa() -> llvm::APInt;
auto GetExponent() -> llvm::APInt;
|
IsInteger()用于判断是否为一个整数,判断方式为小数点位置是否在字符串末尾,字符串显示不存在小数点时,小数点默认在末尾。GetRadix()用于获取进制。GetMantissa()用于获取小数部分。GetExponent()用于获取指数部分。
其中GetMantissa()和GetExponent()都调用了ParseInteger接口,ParseInteger完成获取具体数值的功能,以下为ParseInteger接口代码分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| static auto ParseInteger(llvm::StringRef digits, int radix, bool needs_cleaning)
-> llvm::APInt {
llvm::SmallString<32> cleaned; // 预分配32个字节的字符串
if (needs_cleaning) {
cleaned.reserve(digits.size()); // 根据目标大小重建长度
std::remove_copy_if(digits.begin(), digits.end(),
std::back_inserter(cleaned),
[](char c) { return c == '_' || c == '.'; });
digits = cleaned;
}
llvm::APInt value;
if (digits.getAsInteger(radix, value)) {
llvm_unreachable("should never fail");
}
return value;
}
|
当解析包含小数点和下划线的字面量时,将忽视这两种字符,例如在解析 123.456e7 字面量时,我们期望获取到小数部分mantissa即(123456)和指数部分exponent(7-3=4),根据这两个数我们能计算出真实的数据为:1234560000,其中GetMantissa函数如下:
1
2
3
4
5
6
| auto NumericLiteralToken::Parser::GetMantissa() -> llvm::APInt {
// 如果为整数从int_part为结尾,否则以fract_part为结尾
const char* end = IsInteger() ? int_part.end() : fract_part.end();
llvm::StringRef digits(int_part.begin(), end - int_part.begin());
return ParseInteger(digits, radix, mantissa_needs_cleaning);
}
|
获取exponent的函数GetExponent如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| auto NumericLiteralToken::Parser::GetExponent() -> llvm::APInt {
llvm::APInt exponent(64, 0); // 创建64位值为0的exponent对象。
// 如果存在指数部分,就进入这个分支。
if (!exponent_part.empty()) {
// 解析指数部分。这个函数会将字符串形式的指数转换为整数。其中,
// 第一个参数是指数部分,第二个参数10是代表十进制,第三个参数
// 表示解析过程中是否需要进行清理。
exponent = ParseInteger(exponent_part, 10, exponent_needs_cleaning);
// 检查指数的符号位是否被设置,或者指数的位宽是否小于64。
// 如果满足这些条件之一,就需要扩展指数的位宽。
if (exponent.isSignBitSet() || exponent.getBitWidth() < 64) {
// 扩展指数的位宽。新的位宽至少为64,如果原来的位宽+1大于64,
// 那么就使用原来的位宽+1。扩展后,新增的位都被设置为0。
exponent = exponent.zext(std::max(64U, exponent.getBitWidth() + 1));
}
// 如果指数是负数,就需要取反。
if (exponent_is_negative) {
exponent.negate(); // 取反操作。
}
}
// 计算小数部分的字符数量,这个数量会影响实际的指数大小。
int excess_exponent = fract_part.size();
// 如果基数是16,即如果是十六进制的数,那么每一个小数部
// 分的字符都会减少4个指数(因为一个十六进制的字符等于4个二进制位)。
if (radix == 16) {
excess_exponent *= 4; // 将小数部分的字符数量乘以4。
}
exponent -= excess_exponent; // 从指数中减去小数部分的字符数量。
// 如果原来的指数是负数,但是计算后的指数变为非负,那么就进入这个分支。
if (exponent_is_negative && !exponent.isNegative()) {
// 扩展指数的位宽,新增的位被设置为0。
exponent = exponent.zext(exponent.getBitWidth() + 1);
// 设置指数的符号位,使得指数变为负数。
exponent.setSignBit();
}
return exponent;
}
|
从上面我们可以看到mantissa_needs_cleaning和exponent_needs_cleaning永远为false,原因是因为这两个标志位需要在获取数据之前对字面量做检查后进行设置,对传入不满足要求的字面量做预处理检查后才允许提取。
关于字面量检查部分在下一章Chapter2: 诊断信息中进行说明与分析。
2. 字符串字面量#
// TODO: 1. 讲解字符串字面量代码。// TODO: 2. 讲解字符串字面量设计。
// TODO: 3. utf-8讲解。
// TODO: 4. 单元测试讲解
// TODO: 4.1 c++中的R字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
auto StringLiteral::Lex(llvm::StringRef source_text)
-> std::optional<StringLiteral> {
int64_t cursor = 0;
const int64_t source_text_size = source_text.size();
// 确定前缀中的#数量。
while (cursor < source_text_size && source_text[cursor] == '#') {
++cursor;
}
const int hash_level = cursor;
const std::optional<Introducer> introducer =
Introducer::Lex(source_text.substr(hash_level));
if (!introducer) {
return std::nullopt;
}
cursor += introducer->prefix_size;
const int prefix_len = cursor;
// 初始化终结符和转义序列标记。
llvm::SmallString<16> terminator(introducer->terminator);
llvm::SmallString<16> escape("\\");
// 整终结符和转义序列的大小。
terminator.resize(terminator.size() + hash_level, '#');
escape.resize(escape.size() + hash_level, '#');
/// TODO: 在找到终结符之前检测多行字符串字面量的缩进/反缩进。
for (; cursor < source_text_size; ++cursor) {
// 快速跳过不感兴趣的字符。
static constexpr CharSet InterestingChars = {'\\', '\n', '"', '\''};
if (!InterestingChars[source_text[cursor]]) {
continue;
}
// 多字符的终结符和转义序列都以可预测的字符开始,
// 并且不包含嵌入的、未转义的终结符或换行符。
switch (source_text[cursor]) {
case '\\': // 处理转义字符。
if (escape.size() == 1 ||
source_text.substr(cursor + 1).startwith(escape.substr(1))) {
cursor += escape.size();
// 单行字符串且转义字符是换行符。
if (cursor >= source_text_size || (introducer->kind == NotMultiLine &&
source_text[cursor] == '\n')) {
llvm::StringRef text = source_text.take_front(cursor);
return StringLiteral(text, text.drop_front(prefix_len), hash_level,
introducer->kind,
/*is_terminated=*/false);
}
}
break;
case '\n':
// 单行字符串。
if (introducer->kind == NotMultiLine) {
llvm::StringRef text = source_text.take_front(cursor);
return StringLiteral(text, text.drop_front(prefix_len), hash_level,
introducer->kind,
/*is_terminated=*/false);
}
break;
case '"':
case '\'':
if (source_text.substr(cursor).startswith(terminator)) {
llvm::StringRef text =
source_text.substr(0, cursor + terminator.size());
llvm::StringRef content =
source_text.substr(prefix_len, cursor - prefix_len);
return StringLiteral(text, content, hash_level, introducer->kind,
/*is_terminated=*/true);
}
break;
default:
// 对于非终结符,不执行任何操作。
break;
}
}
return StringLiteral(source_text, source_text.drop_front(prefix_len),
hash_level, introducer->kind,
/*is_terminated=*/false);
}
|
首先,我们需要理解代码的逻辑以构建自动机。这段代码的主要目的是解析字符串字面量,特别是处理多行字符串、转义序列和终结符。
基于代码的逻辑,我们可以构建以下自动机,以下是自动机图示:
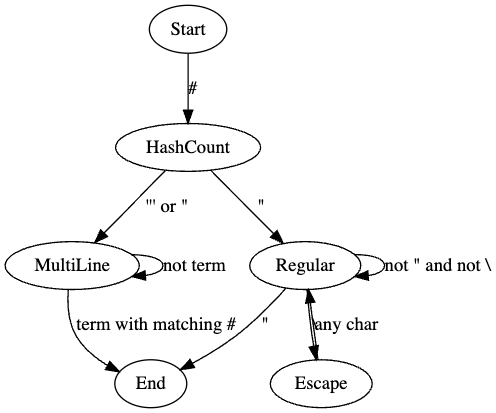
首先,我们需要理解自动机的基本概念。在计算机科学中,一个自动机是一个抽象的机器,它可以处于有限数量的不同状态之一,且在任何给定时刻只能处于其中一个状态。自动机根据输入序列中的符号进行状态转换。
现在,让我们详细分析上述自动机的每个部分:
开始状态 (Start): 这是解析字符串时的初始状态。在这个状态下,我们首先检查字符串的前缀是否包含#字符。
HashCount: 在这个状态下,我们计算#的数量。这是为了确定多行字符串的终结符需要与开始的#数量匹配。
多行状态 (MultiLine): 如果字符串以'''或"""开始,我们进入这个状态。在这个状态下,我们查找与开始匹配的终结符。终结符需要与开始的#数量匹配。
常规状态 (Regular): 如果字符串以一个双引号"开始,我们进入这个状态。在这个状态下,我们查找另一个双引号或转义序列。
转义状态 (Escape): 当我们在常规状态下遇到反斜杠\时,我们进入这个状态。这是因为反斜杠通常用于表示转义序列,例如\"表示一个双引号字符。在这个状态下,我们查找与转义序列匹配的字符。
结束状态 (End): 当我们找到与开始匹配的终结符或达到字符串的末尾时,我们进入这个状态。这表示我们已经成功地解析了整个字符串。
为什么这个自动机是这样设计的?
这个自动机是基于Carbon语言中字符串字面量的词法规则设计的。这些规则定义了如何从源代码中解析字符串。特别是,这个自动机处理了以下几点:
#字符的数量,这决定了多行字符串的终结符。- 多行字符串和常规字符串的区别。
- 转义序列,这是在常规字符串中表示特殊字符的方法。
通过这个自动机,我们可以准确地解析Carbon语言中的字符串字面量,无论它们是多行的、常规的还是包含转义序列的。
字符串解析例子:
对于输入###'''hello world'''###:
- 我们首先计算
#的数量为3。 - 然后,我们确定这是一个多行字符串,并查找与
'''###匹配的终结符。 - 我们成功地找到了终结符并结束了解析。
对于输入"hello \\" world":
- 我们确定这是一个常规字符串。
- 我们继续解析,直到遇到反斜杠
\,然后进入转义状态。 - 在转义状态下,我们找到另一个反斜杠,并返回常规状态。
- 我们继续解析,直到找到终结符
"并结束解析。
这个自动机提供了一个高层次的视图,描述了如何解析字符串字面量。
StringLiteral中静态函数的逐行分析#
- ComputeIndentOfFinalLine
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| // 计算给定文本中最后一行的缩进(即最后一行前面的水平空白字符序列)。
static auto ComputeIndentOfFinalLine(llvm::StringRef text) -> llvm::StringRef {
int indent_end = text.size(); // 从文本的末尾开始,逐字符向前检查。
for (int i = indent_end - 1; i >= 0; --i) {
if (text[i] == '\n') { // 如果遇到换行符\n,则该位置之后的所有字符都是最后一行的缩进。
int indent_start = i + 1;
return text.substr(indent_start, indent_end - indent_start);
}
if (!IsSpace(text[i])) { // 如果遇到非空格字符,则更新缩进的结束位置。
indent_end = i;
}
}
// 如果没有找到换行符,这意味着给定的文本不包含换行符,这是一个错误情况。
llvm_unreachable("Given text is required to contain a newline.");
}
|
这段代码定义了一个函数 ComputeIndentOfFinalLine,它的目的是计算给定文本中最后一行的缩进(即最后一行前面的水平空白字符序列)。
让我们逐步分析这段代码:
函数签名:
1
| static auto ComputeIndentOfFinalLine(llvm::StringRef text) -> llvm::StringRef
|
这个函数接受一个 llvm::StringRef 类型的参数 text,并返回一个 llvm::StringRef 类型的结果。llvm::StringRef 是一个轻量级的字符串引用,它不拥有其引用的字符串的内存,但提供了对该字符串的高效访问。
初始化:
1
| int indent_end = text.size();
|
初始化 indent_end 为文本的长度。这是因为我们将从文本的末尾开始向前搜索,以找到最后一个换行符。
查找最后一个换行符:
1
2
3
4
5
6
7
8
9
| for (int i = indent_end - 1; i >= 0; --i) {
if (text[i] == '\n') {
int indent_start = i + 1;
return text.substr(indent_start, indent_end - indent_start);
}
if (!IsSpace(text[i])) {
indent_end = i;
}
}
|
这个循环从文本的末尾开始,向前搜索直到找到最后一个换行符或到达文本的开始。如果找到一个非空白字符,它会更新 indent_end 的值。当找到换行符时,函数会返回从该换行符之后到 indent_end 之间的子字符串,这就是最后一行的缩进。
异常情况:
1
| llvm_unreachable("Given text is required to contain a newline.");
|
如果函数没有在文本中找到换行符,它会触发一个不可达的断言,表示这是一个异常情况。这意味着调用此函数的代码应确保提供的文本至少包含一个换行符。
测试用例:
基本用例:
1
2
| llvm::StringRef test1 = "Hello\n World";
assert(ComputeIndentOfFinalLine(test1) == " ");
|
这个测试用例有两行,最后一行的缩进是两个空格。
没有缩进的用例:
1
2
| llvm::StringRef test2 = "Hello\nWorld";
assert(ComputeIndentOfFinalLine(test2) == "");
|
这个测试用例的最后一行没有缩进。
只有一个换行符的用例:
1
2
| llvm::StringRef test3 = "\n";
assert(ComputeIndentOfFinalLine(test3) == "");
|
这个测试用例只有一个换行符,所以最后一行没有缩进。
异常用例:
1
2
3
| llvm::StringRef test4 = "Hello World";
// This should trigger the llvm_unreachable assertion
ComputeIndentOfFinalLine(test4);
|
这个测试用例没有换行符,所以应该触发不可达的断言。
注意:在实际使用中,你可能需要确保提供给 ComputeIndentOfFinalLine 的文本至少包含一个换行符,以避免触发异常。
spec#
Carbon 支持使用一个双引号(")的单行简单字面量和使用三个单引号(''')的多行块状字面量。块状字符串字面量在第一个'''后可能有一个文件类型指示器;这对字符串本身没有影响,但可能有助于其他工具。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| // 简单字符串字面量:
var simple: String = "example";
// 块状字符串字面量:
var block: String = '''
The winds grow high; so do your stomachs, lords.
How irksome is this music to my heart!
When such strings jar, what hope of harmony?
I pray, my lords, let me compound this strife.
-- History of Henry VI, Part II, Act II, Scene 1, W. Shakespeare
''';
// 块状字符串字面量带有文件类型指示器:
var code_block: String = '''cpp
#include <iostream>
int main() {
std::cout << "Hello world!";
return 0;
}
'''
|
块状字符串字面量的终止行的缩进从所有前面的行中删除。因此,在上面的code_block示例中,只有std::cout和return在结果字符串中有缩进,每个都是4个空格。
由反斜杠(\)引入的转义序列用于表示特殊字符或代码单元序列,例如\n表示换行符。原始字符串字面量还用一个或多个#进行分隔;这些在\后需要相同数量的井号符号(#)来表示转义序列。原始字符串字面量用于更容易地在字符串中写入字面量\。简单和块状字符串字面量都有原始形式。例如:
1
2
3
4
5
6
7
8
| // 带有换行转义序列的原始简单字符串字面量:
var newline: String = "line one\nline two";
// 带有字面量`\n`的原始简单字符串字面量,不是换行:
var raw: String = #"line one\nstill line one"#;
// 带有换行转义序列的原始简单字符串字面量:
var raw_newline: String = #"line one\#nline two"#;
|
详细信息#
简单和块状字符串字面量#
简单字符串字面量由以下序列组成:
- 除
\和"之外的字符。- 在字符串字面量中,只有空格字符(U+0020)是有效的空白。
- 其他水平空白,包括制表符,是不允许的,但为了错误恢复目的被解析为字符串的一部分。
- 垂直空白不会被解析为简单字符串字面量的一部分。
- 转义序列。
- 每个转义序列都被替换为相应的字符序列或代码单元序列。
- 与无效的空白类似,无效的转义序列,如
\z,被解析为字符串的一部分。
这个序列被包含在"中。例如,这是一个简单的字符串字面量:
1
| var String: lucius = "The strings, my lord, are false.";
|
不允许相邻的字符串字面量,如下所示:
1
2
| // 三个相邻的简单字符串字面量`""`、`"abc"`和`""`是无效的。
var String: block = """abc""";
|
以三个双引号"""开始的字符串字面量是相邻的字符串字面量。拒绝并诊断它们是很重要的。
块状字符串字面量以'''开始。'''后面的同一行上的字符是一个可选的文件类型指示器。字面量在下一个三个单引号的实例结束,其中第一个'不是\'转义序列的一部分。关闭的'''应该是那一行的第一个非空白字符。开头行和结束行之间的行(不包括)是内容行。内容行不应包含不形成转义序列一部分的\字符。
块状字符串字面量的缩进是终止行前的水平空白序列。每个非空内容行都应该以字符串字面量的缩进开始。字面量的内容如下形成:
- 从每个非空内容行中删除终止行的缩进。
- 每行的所有尾随空白,包括行终止符,都被替换为一个换行符(U+000A)。
- 结果行被连接起来。
- 每个转义序列都被替换为相应的字符序列或代码单元序列。
如果内容行只包含空白字符,则认为它是空的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| // 所有块状字符串字面量默认包含一个尾随换行符。
var String: newline_example = '''
This is a block string literal. Its first character is 'T' and its last character is
a newline. It contains another newline character between 'is' and 'a'.
''';
// 可以使用转义字符'\'来抑制换行符
var String: suppressed_newlines = '''
This is another block string literal. The newline character here \
is suppressed, along with the trailing newline here.\
''';
// 这个块状字符串字面量是无效的,因为'closing'后面的'''终止了字面量,但它不在行的开头。
var String: invalid = '''
error: closing ''' is not on its own line.
''';
|
文件类型指示器是除'或#之外的任何非空白字符序列。文件类型指示器对 Carbon 编译器没有语义意义,但某些文件类型指示器被语言工具(例如,语法高亮器,代码格式化器)理解为指示字符串字面量内容的结构。
1
2
3
4
5
| // 这是一个块状字符串字面量。它的前两个字符是空格,它的最后一个字符是换行符。它有一个文件类型为'c++'。
var String: starts_with_whitespace = '''c++
int x = 1; // 这一行以两个空格开始。
int y = 2; // 这一行以两个空格开始。
''';
|
文件类型指示器可能包含超出文件类型本身的语义信息,例如指示代码格式化器为代码块禁用格式化的指令。
开放问题: 没有明确的已识别文件类型指示器集。非正式地指定一组众所周知的指示器将是有用的,这样工具就可以对这些指示器的含义有一个共同的理解,也许在最佳实践指南中。
转义序列#
在字符串字面量中,以下转义序列被识别:
| 转义 | 含义 |
|---|
\t | U+0009 字符制表符 |
\n | U+000A 换行符 |
\r | U+000D 回车符 |
\" | U+0022 引号 (") |
\' | U+0027 逗号 (') |
\\ | U+005C 反斜杠 (\) |
\0 | 值为0的代码单元 |
\0D | 无效,为未来的发展保留 |
\xHH | 值为HH16的代码单元 |
\u{HHHH...} | Unicode 代码点 U+HHHH… |
\<newline> | 无字符串字面量内容产生 (仅限块状字面量) |
十六进制字符(H)必须为大写(\xAA,而不是\xaa)。
这包括所有C++转义序列,除了:
\?,它在字符串字面量中历史上用于转义三字符组,现在不再有任何用途。\ooo 八进制转义,因为Carbon不支持八进制字面量;\0作为一个特殊情况被保留,这对于C互操作性预计是很重要的。\uABCD,被\u{ABCD}替代。\U0010FFFF,被\u{10FFFF}替代。\a (铃声),\b (退格),\v (垂直制表符),和\f (换页)。\a和\b已经过时,\f和\v基本上已经废弃。如果需要,这些字符可以分别用\x07、\x08、\x0B和\x0C表示。
注意,这是由Swift和Rust支持的相同的转义序列集,除了与Swift不同,它提供了对\xHH的支持。
尽管预计八进制转义序列将继续不被允许(尽管\0D被保留),但决定不支持\1..\7或更一般地\DDDD是_实验性的_。
在上表中,H表示任意十六进制字符,0-9或A-F(区分大小写)。与C++不同,但与Python相似,\x期望恰好两个十六进制数字。与JavaScript、Rust和Swift一样,可以使用\u{10FFFF}表示法按数字表示Unicode代码点。这接受1到8个十六进制字符。可以用这种方式表示016-D7FF16或E00016-10FFFF16范围内的任何数字代码点。
开放问题: 一些编程语言(尤其是Python)支持\N{unicode character name}语法。我们可以添加这样的转义序列。未来考虑添加此类支持的提案应注意C++的Unicode研究小组在此领域的工作。
转义序列\0不应该后跟十进制数字。在应该在空字节后跟随十进制数字的情况下,可以使用\x00代替:"foo\x00123"。目的是保留将来允许十进制转义序列的可能性。
反斜杠后跟换行符是一个不产生字符串内容的转
义序列。这个转义序列是_实验性的_,只能出现在块状字符串字面量中。这个转义序列在替换尾随空白后处理为换行符之后进行处理,所以一个\后跟水平空白后跟一个行终止符会移除直到并包括行终止符的空白。与Rust不同,但与Swift相似,换行符后的转义新行的前导空白不会被移除,除了与终止'''的缩进匹配的空白。
以反斜杠开头的字符序列,如果不匹配任何已知的转义序列,则无效。除了空格和块状字符串字面量的新行(可选地前置回车)之外,其他空白字符是不允许的。所有其他字符(包括不可打印字符)都被原样保留。因为所有的Carbon源文件都要求是有效的Unicode字符序列,所以只能通过\x转义序列产生不是有效的UTF-8的代码单元序列。
决定在字符串字面量中不允许原始制表符是_实验性的_。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| var String: fret = "I would 'twere something that would fret the string,\n" +
"The master-cord on's \u{2764}\u{FE0F}!";
// 这个字符串包含两个字符(在编码为UTF-8之前):
// U+1F3F9 (弓和箭) 后跟 U+0032 (数字二)
var String: password = "\u{1F3F9}2";
// 这个字符串不包含换行符。
var String: type_mismatch = '''
Shall I compare thee to a summer's day? Thou art \
more lovely and more temperate.\
''';
var String: trailing_whitespace = '''
This line ends in a space followed by a newline. \n\
This line starts with four spaces.
''';
|
原始字符串字面量#
为了允许字符串的内容包括\和",可以通过在开头的定界符前加上_N_个#字符来自定义字符串字面量的定界符。这样的字符串的关闭定界符只有在后面跟着_N_个#字符时才会被识别,同样地,这样的字符串字面量中的转义序列只有在\后面也跟着_N_个#字符时才会被识别。一个\、"或'''后面没有跟着_N_个#字符没有特殊意义。
| 开始定界符 | 转义序列引入符 | 结束定界符 |
|---|
" / ''' | \ (例如, \n) | " / ''' |
#" / #''' | \# (例如, \#n) | "# / '''# |
##" / ##''' | \## (例如, \##n) | "## / '''## |
###" / ###''' | \### (例如, \###n) | "### / '''### |
| … | … | … |
例如:
1
2
3
4
5
6
7
8
9
| var String: x = #'''
这是字符串的内容。'T'是字符串的第一个字符。
''' <-- 这不是字符串的结尾。
'''#;
// 但前面的那行确实结束了字符串。
// OK, 最后一个字符是\
var String: y = #"Hello\"#;
var String: z = ##"Raw strings #"nesting"#"##;
var String: w = #"Tab is expressed as \t. Example: '\#t'"#;
|
字符串字面量产生一个8位字节的序列。像Carbon源文件一样,字符串字面量使用UTF-8编码。然而,不能保证字符串是有效的UTF-8,因为可以通过\xHH转义序列插入任意字节序列。
这是_实验性的_,如果我们发现直接表示其他编码的字符串字面量的足够动机,应该重新考虑。同样,随着库对字符串类型的支持的发展,我们应该考虑包括字符串字面量语法(也许作为默认值),保证字符串内容是有效的UTF-8编码,这样在类型系统中可以区分有效的UTF-8和任意字符串。在这样的字符串字面量中,我们应该考虑拒绝HH大于7F16的\xHH转义,如Rust中所做的那样。